2021.05.19|インタビュー
文系社員が始める予測分析入門

近年、ノーコーディングでWebサイトやアプリ制作などができるサービスも立ち上がり、専門的な知識を保有せずともデジタルツールの開発ができるトレンドが、AIにもきています。
この流れは「AIの民主化」と呼ばれており、AIを専門分野としないビジネスサイドでもAIの活用を実務に取り入れる環境が整いつつありますが、一方で、AIについて「導入を検討しているが、何から始めて良いかわからない」といった声も度々聞きます。
今、ビジネスデータにAIを適用することで将来の結果を予測する予測分析が注目されており、適用できる領域の広さ・試しやすさから、予測分析は今ビジネスで使えるAIと言っても過言ではありません。
このようなAIの民主化の代表的な予測分析ツールの一つとして挙げられるのが、弊社の提供する「Prediction One」。今回は、弊社サービス企画の金子直樹に、予測分析によって算出できる結果の種類とPrediction Oneの特長・使用方法を文系出身の担当者が聞きました。

他社製品と比較したPrediction Oneの特長について
― Prediction Oneが「専門家ではなくても使える予測分析ツール」ということで、文系の私でも使えるのではないかと期待しております。まずは、Prediction Oneの開発背景を聞かせてください。
AIを既に活用している企業も一部ありますが、多くの企業ではデータをAIに転用する知識を有したデータサイエンティストといった専門家がおらず、これがAIのビジネス利用が普及しない理由の一つです。
そのギャップを埋めるために開発されたのが、Prediction Oneです。
― 金子さんは他社製品を使用していたかと思いますが、違いは何でしょうか?
前職で予測分析ツールを活用していましたが、機械学習の知識や、ITスキルが必要な製品が多く、初学者にとってハードルが高いツールが多いと思います。
他の製品は、機械学習モデルの選択、プログラミングでの実装、閾値(しきいち)の選択など、細かい設定ができる反面、機械学習への理解、操作方法を覚える必要があります。Prediction Oneは、そのような複雑な設定や知識がなくとも簡単にご利用いただけます。
Prediction Oneであれば、使いやすいユーザビリティで専門知識がなくても数クリックで予測結果が出ますので、AIの民主化の一端を担っていると自負しています。
まず、予測分析をする際には「予測モデル」を作成するための最適な機械学習のアルゴリズムを選択・作成する必要があります。
例えば、見込み顧客のサービスの成約率を予測したいのであれば、これまでの顧客の年齢や性別、サービスの使用頻度などのステータスが予測モデルに必要なデータで、このデータを学習データ(教師データ)と呼びます。
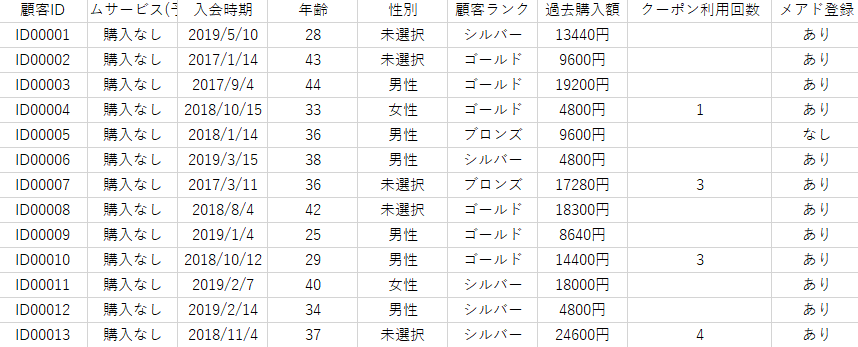
学習データの一例(Prediction Oneデモファイル「1_プレミアムサービス購入.csv」より)
Prediction Oneは、学習データを読み込んで自動的に最適なアルゴリズムを算出され、各データ項目が寄与度として有益なものを可視化できます。
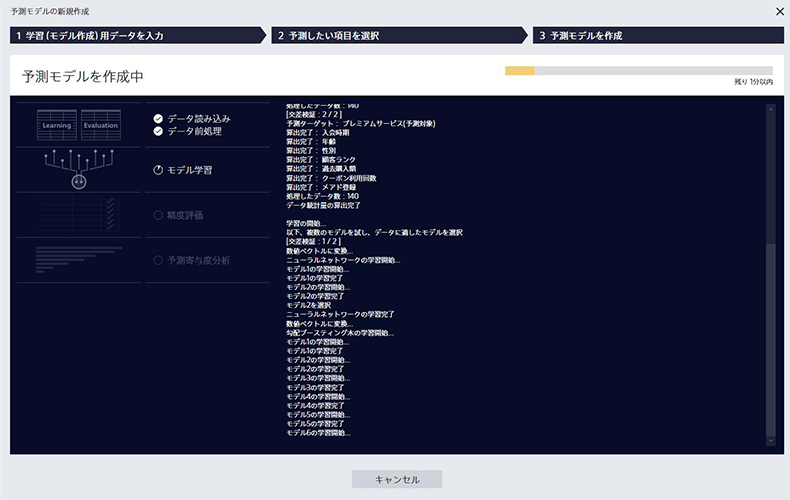
複数の計算モデルと照合して最適なモデルを作成
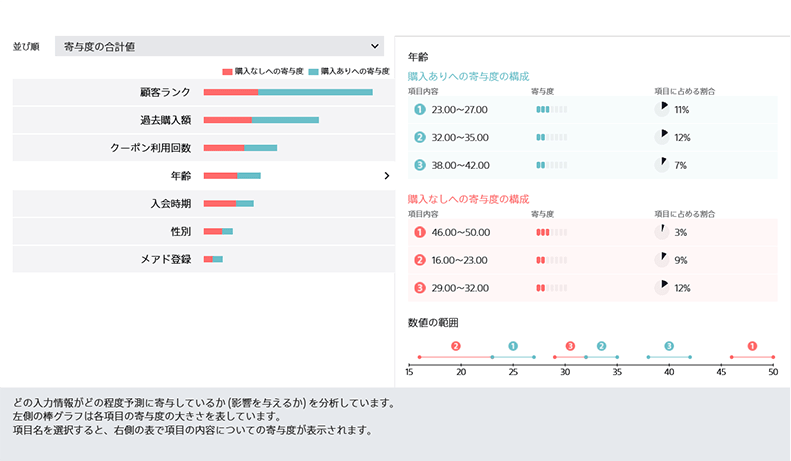
各項目の寄与度を可視化
― 項目ごとに寄与度が出ているので「実はこの情報が貢献している」と新たな発見につながるかもしれませんね。
「精度の詳細」では、単語の意味やグラフの詳細を文系の人でもわかりやすく丁寧に説明しているのが特徴です。学習データを加工したら予測モデルを作り「予測する」ボタンをクリックすることで、結果が算出されます。
― わかりやすいUI、クリックの動作だけで簡単に予測分析ができそうで、文系の私でも使えそうです!
予測したいことを起点としたデータの準備が大切
― 学習データの作成をする際は、何から始めれば良いでしょうか?
まずは、何を予測したいかを決めてください。それによって学習データの作り方が変わります。
用意するものは、過去のデータを加工した学習データと予測する項目の列を空けた将来のデータの2つです。
― 顧客からは、よく「AIの活用を考えていて、データはあるがどのように活用して良いかわからない」といった声を聞きます。
データの加工方法をお伝えする前に、そもそも予測分析でアウトプットできることを説明いたします。アウトプットは、大きく分類(二値、多値)と回帰(数値)の2つに分かれます。
分類
- 二値
- Yes or Noといった二択(例:正解/不正解)
- 多値
- A、B、C、Dと何種類かに分類できる項目(例:ペルソナ)
回帰
- 単純
- 1、2、3、4といった数値(例:PV数やCV数)
- 時系列
- 数値に日時などが追加されたもの(例:〇月〇日のCV数)
そして、予測の精度を高めるには、基本的なデータの他にも周辺データが必要です。
例えば、生命保険の加入者の見込み客を予測したいのであれば、基本データとしては、過去の成約の有無。周辺データは、加入者の地域、年齢、年収、家族構成などになります。
車の買い替え時期を予測するのであれば、現在の車の購入時期を基本データとし、年齢、年収、家族構成、居住地域などが周辺データにあたります。
とある商品の購入であれば、これまでの購入額を基本として、年齢、地域、購入頻度、購入場所などが該当します。
― 分類、回帰などは、日ごろからデータ分析をしていないと耳慣れない言葉ですね。早速Prediction Oneを体験したいです!
初学者であれば、まず二値分類から始めましょう。
例えばマーケターの方であれば、Prediction Oneのチュートリアルにあるデモファイル「1_プレミアムサービス購入.csv」がわかりやすいかと思います。デモファイルの設定として、皆様がある定額制サービスを提供している会社のマーケティング部門の担当者という立場とします。
マーケティング部門では、顧客に対してプレミアムサービスの訴求に電話でアプローチしていますが、全員に電話をかけることはできないうえ、成約率もあまりよくありません。そこで、これまで社員の勘に頼っていたアプローチをPrediction Oneによってターゲティングの改善を図ります。
― 学習データ項目は、顧客ID以外のプレミアムサービス(予測対象)、入会時期、年齢、性別、顧客ランク、過去購入額、クーポン利用回数、メールアドレスの有無の8項目ですね。
顧客IDは、300名弱あります。
顧客データは、担当部署で管理されているかと思いますが、項目は多ければ多いほど精緻な予測結果が算出されます。予測モデルの作成では、これらの項目をもって「購入するかしないか」を学習させます。csvで作成した学習データをPrediction One内の「予測モデルの新規作成」をクリックして取り込んでください。
― 学習データのcsvがPrediction One内の画面上に瞬時に表示されますね。画面上の操作だけで済む点が担当者に嬉しい機能です。
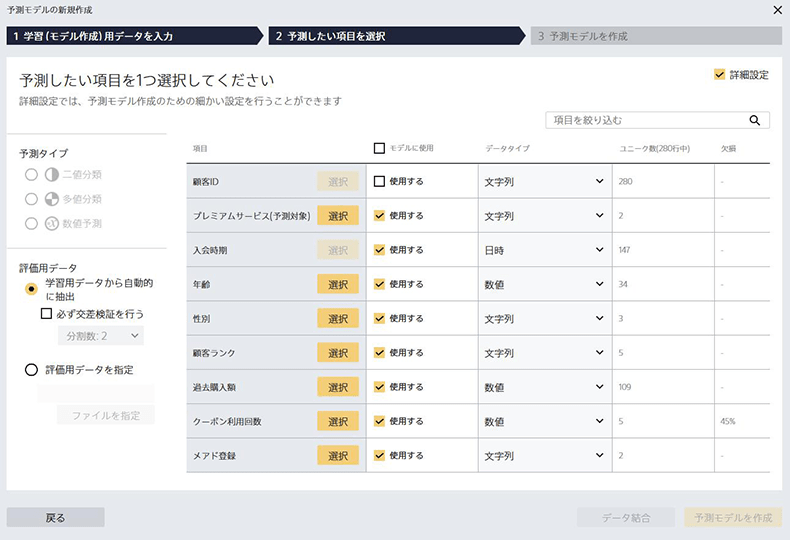
今回は、プレミアムサービスを購入するかしないかを知りたいので「プレミアムサービス(予測対象)」という項目を選択し、「予測モデルを作成」をクリックしてください。
― データの量にも左右されるかと思いますが、数分ほどで作成完了するのですね。先ほど金子さんが言及していた、作成されたモデルの精度評価もここで見ることができます。
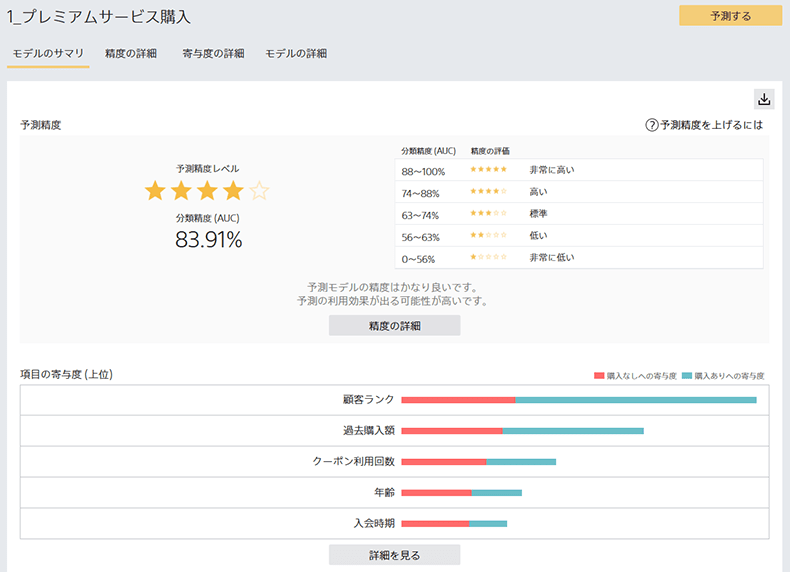

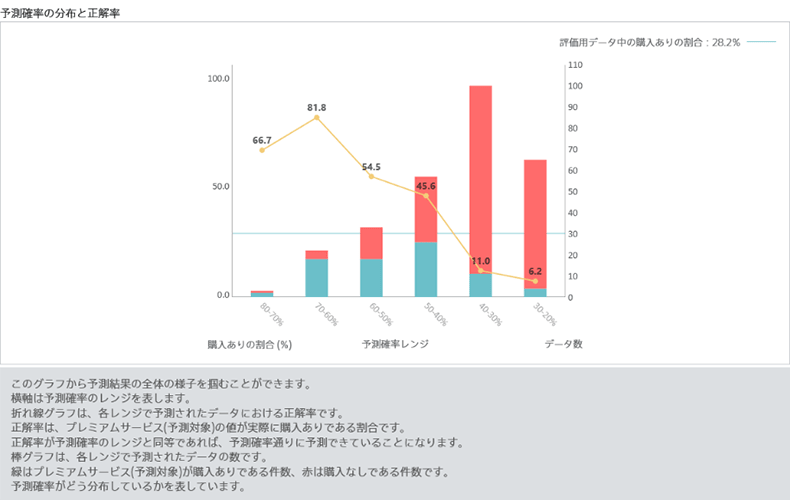
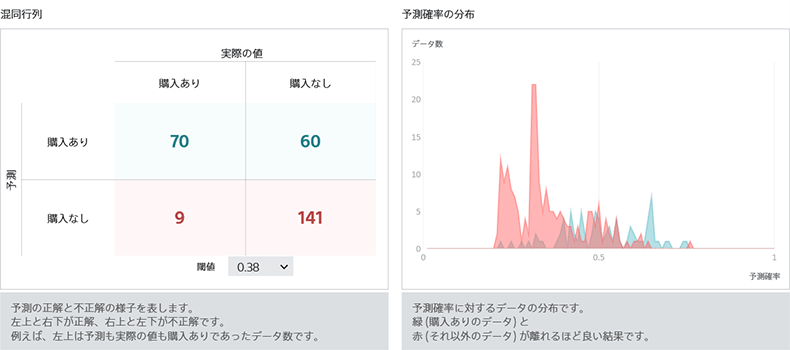
予測モデルの次は、いよいよプレミアムサービスの購入するかどうかわかっていない顧客に対しての購入確率を予測します。プレミアムサービス購入あり・なしの項目を空欄にした将来データを取り込んでください。
― ここでもデータを取り込めば予測結果のプレビューが見られるのですね。さらに「購入する」の結果を厳しめに出すかどうかの閾値もここで変えられるので、CVの目標数値の調整も簡単にできます。
予測結果には、なぜ「購入する」に結論付けたか理由も記載されているので、社内説得用にも利用できます。
― シンプルでわかりやすいUIと操作方法だけでなく、ところどころに見られる担当者の使い勝手につながる便利機能が好評いただいている理由なのですね。
最後に
今回は、予測分析によって得られる結果の種類とPrediction Oneの使用方法を教えていただきました。次回はサンプルデータではなく、自分でデータの加工方法に挑戦したいと思います!
今回使用した、予測分析ソフト「Prediction One」は、30日間無料でお試しいただけます。